本文介绍tensorflow中的一些基本概念,并说明如何可视化训练过程
Variable
在 Tensorflow 中,定义了某字符串是变量,它才是变量,这一点是与 Python 所不同的。
定义语法: state = tf.Variable()
import tensorflow as tf
state = tf.Variable(0, name='counter')
# 定义常量 one
one = tf.constant(1)
# 定义加法步骤 (注: 此步并没有直接计算)
new_value = tf.add(state, one)
# 将 State 更新成 new_value
update = tf.assign(state, new_value)
如果你在 Tensorflow 中设定了变量,那么初始化变量是最重要的! 所以定义了变量以后, 一定要定义 init = tf.initialize_all_variables() .
到这里变量还是没有被激活,需要再在 sess 里, sess.run(init) , 激活 init 这一步.
# 如果定义 Variable, 就一定要 initialize
# init = tf.initialize_all_variables() # tf 马上就要废弃这种写法
init = tf.global_variables_initializer() # 替换成这样就好
# 使用 Session
with tf.Session() as sess:
sess.run(init)
for _ in range(3):
sess.run(update)
print(sess.run(state))
注意:直接 print(state) 不起作用!!
一定要把 sess 的指针指向 state 再进行 print 才能得到想要的结果!
placeholder
placeholder 是 Tensorflow 中的占位符,暂时储存变量.
Tensorflow 如果想要从外部传入data, 那就需要用到 tf.placeholder(), 然后以这种形式传输数据 sess.run(***, feed_dict={input: **}).
示例:
import tensorflow as tf
#在 Tensorflow 中需要定义 placeholder 的 type ,一般为 float32 形式
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
# mul = multiply 是将input1和input2 做乘法运算,并输出为 output
ouput = tf.multiply(input1, input2)
接下来, 传值的工作交给了 sess.run() , 需要传入的值放在了feed_dict={} 并一一对应每一个 input. placeholder 与 feed_dict={} 是绑定在一起出现的。
with tf.Session() as sess:
print(sess.run(ouput, feed_dict={input1: [7.], input2: [2.]}))
# [ 14.]
add_layer
定义一个添加神经层的函数对与以后构建神经网络会有很大的便利性。 神经层里常见的参数有weights,biases和激活函数。 函数参数包括输入值以及输入值的大小,输出的大小以及激活函数。 初始化的时候weights随机生成,biases不推荐为0,所以加0.1。 wx_plus_b表示未激活的输出值。
def add_layer(inputs, in_size, out_size, activation_function=None):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
一元二次函数的训练
定义一个单输入单输出,隐藏层包含十个神经元的网络结构进行训练。
import tensorflow as tf
import numpy as np
def add_layer(inputs, in_size, out_size, activation_function=None):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1)
Wx_plus_b = tf.matmul(inputs, Weights) + biases
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b)
return outputs
#导入数据,并加入noise
x_data = np.linspace(-1,1,300, dtype=np.float32)[:, np.newaxis]
noise = np.random.normal(0, 0.05, x_data.shape).astype(np.float32)
y_data = np.square(x_data) - 0.5 + noise
#数据以placeholder格式输入,1表示只有一个特征,None表示不限大小
xs = tf.placeholder(tf.float32, [None, 1])
ys = tf.placeholder(tf.float32, [None, 1])
#构建1*10*1的神经网络
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
prediction = add_layer(l1, 10, 1, activation_function=None)
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
init = tf.global_variables_initializer() # 替换成这样就好
sess = tf.Session()
sess.run(init)
for i in range(1000):
# training
sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
if i % 50 == 0:
# to see the step improvement
print(sess.run(loss, feed_dict={xs: x_data, ys: y_data}))
for循环里面xs如何更新的? for表示训练轮数,每一轮都把所有的数据给处理完。
tensorboard 可视化
显示网络结构
使用tensorboard可视化我们构建的网络,可以直观的显示出神经网络的结构。
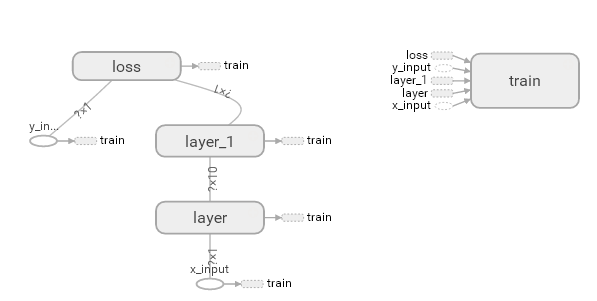 可以点开每一个layer查看layer内部的元素。
可以点开每一个layer查看layer内部的元素。
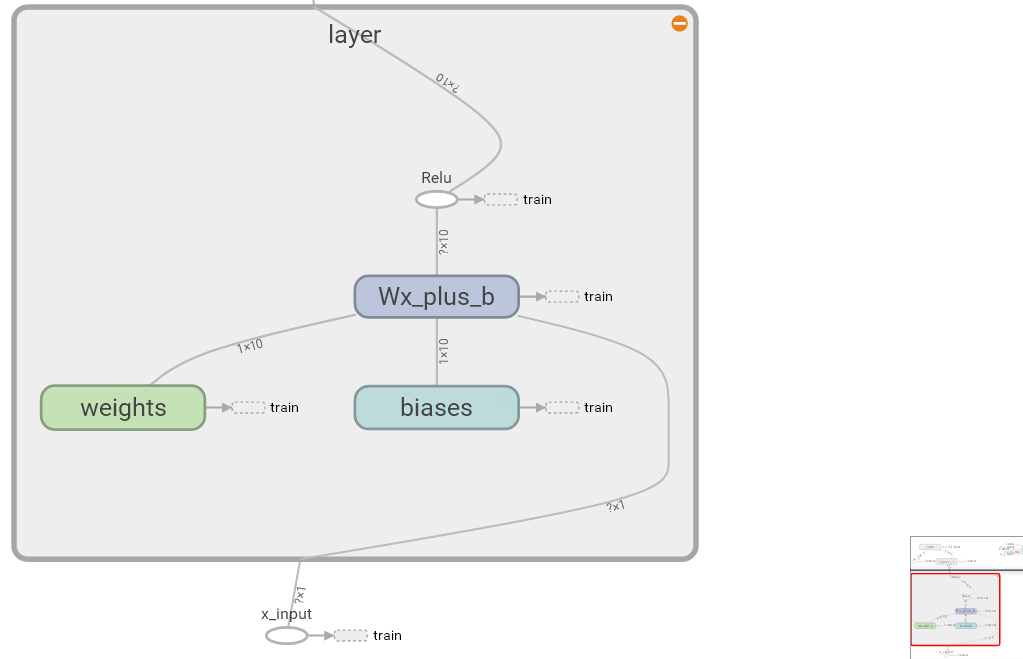
实现方式就是在需要显示的之前添加with tf.name_scope('**'):,例如上面例子中添加如下:
from __future__ import print_function
import tensorflow as tf
def add_layer(inputs, in_size, out_size, activation_function=None):
# add one more layer and return the output of this layer
with tf.name_scope('layer'):
with tf.name_scope('weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='W')
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b')
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
return outputs
# define placeholder for inputs to network
with tf.name_scope('inputs'):
xs = tf.placeholder(tf.float32, [None, 1], name='x_input')
ys = tf.placeholder(tf.float32, [None, 1], name='y_input')
# add hidden layer
l1 = add_layer(xs, 1, 10, activation_function=tf.nn.relu)
# add output layer
prediction = add_layer(l1, 10, 1, activation_function=None)
# the error between prediciton and real data
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
with tf.name_scope('train'):
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
sess = tf.Session()
# tf.train.SummaryWriter soon be deprecated, use following
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1: # tensorflow version < 0.12
writer = tf.train.SummaryWriter('logs/', sess.graph)
else: # tensorflow version >= 0.12
writer = tf.summary.FileWriter("logs/", sess.graph)
# tf.initialize_all_variables() no long valid from
# 2017-03-02 if using tensorflow >= 0.12
if int((tf.__version__).split('.')[1]) < 12 and int((tf.__version__).split('.')[0]) < 1:
init = tf.initialize_all_variables()
else:
init = tf.global_variables_initializer()
sess.run(init)
显示训练过程
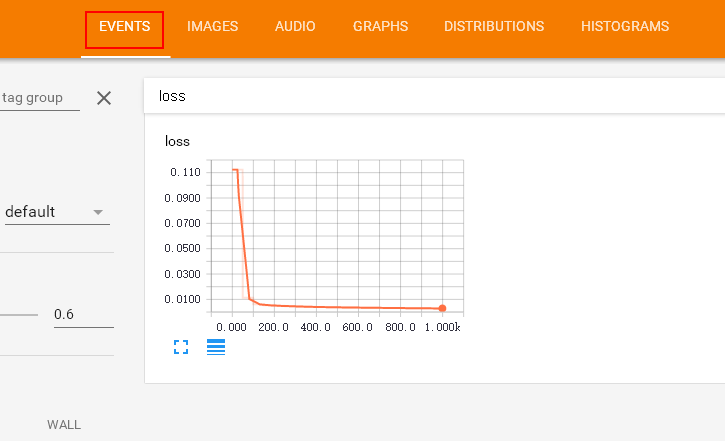
训练过程中的参数变化也可以通过tensorboard显示,常用的是显示出权重的变化,loss的变化,准确率的变化等等。
loss变化:
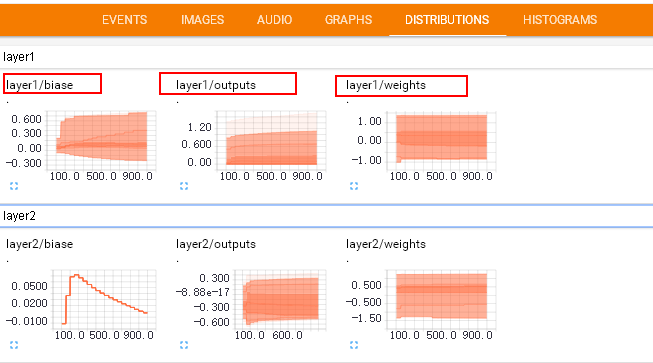
 layer参数变化:
layer参数变化:
from __future__ import print_function
import tensorflow as tf
import numpy as np
def add_layer(inputs, in_size, out_size, n_layer, activation_function=None):
# add one more layer and return the output of this layer
layer_name = 'layer%s' % n_layer #define a new var 因为不同的layer属于不同变量
with tf.name_scope(layer_name):
with tf.name_scope('weights'):
Weights = tf.Variable(tf.random_normal([in_size, out_size]), name='W')
tf.summary.histogram(layer_name + '/weights', Weights) #绘制变量图,第一个是名字,第二个是图标要记录的变量
with tf.name_scope('biases'):
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, name='b')
tf.summary.histogram(layer_name + '/biases', biases)
with tf.name_scope('Wx_plus_b'):
Wx_plus_b = tf.add(tf.matmul(inputs, Weights), biases)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
tf.summary.histogram(layer_name + '/outputs', outputs)
return outputs
# Make up some real data
x_data = np.linspace(-1, 1, 300)[:, np.newaxis]
noise = np.random.normal(0, 0.05, x_data.shape)
y_data = np.square(x_data) - 0.5 + noise
# define placeholder for inputs to network
with tf.name_scope('inputs'):
xs = tf.placeholder(tf.float32, [None, 1], name='x_input')
ys = tf.placeholder(tf.float32, [None, 1], name='y_input')
# add hidden layer
l1 = add_layer(xs, 1, 10, n_layer=1, activation_function=tf.nn.relu)
# add output layer
prediction = add_layer(l1, 10, 1, n_layer=2, activation_function=None)
# the error between prediciton and real data
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.reduce_sum(tf.square(ys - prediction),
reduction_indices=[1]))
tf.summary.scalar('loss', loss)
with tf.name_scope('train'):
train_step = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
sess = tf.Session()
merged = tf.summary.merge_all()
writer = tf.summary.FileWriter("logs/", sess.graph)
init = tf.global_variables_initializer()
sess.run(init)
for i in range(1000):
sess.run(train_step, feed_dict={xs: x_data, ys: y_data})
if i % 50 == 0:
result = sess.run(merged,
feed_dict={xs: x_data, ys: y_data})
writer.add_summary(result, i)